常见问题与答案¶
我们编译原理助教众多,希望同学们踊跃提问。同时我们会挑选一些比较有代表性或者提问次数较多的问题放到这里供同学们查阅。
环境配置¶
1.WSL 环境下使用 systemctl 指令报错: System has not been booted with systemd as init system (PID 1). Can’t operate.¶
由于部分 WSL 使用 SysV init 而非 systemd 管理服务,解决方法是使用 service
指令代替 systemctl 指令。
2.如何更新代码仓库: 请在终端依次输入以下指令¶
(注意:你的终端所在目录应在实验代码文件夹根目录下,如果你不确定,请新建终端)
git stash # 将当前未提交的修改暂时储藏
git pull # 从远程仓库拉取新的实验代码
git stash pop # 恢复先前暂时储藏的修改
3.MacOS + VSCode 如何进入单步调试¶
- 安装 VSCode 插件
CodeLLDB

- 在
.vscode/launch.json中加入以下配置
{
"type": "lldb",
"request": "launch",
"name": "Launch",
"program": "${cmake.testProgram}",
"args": ["${cmake.testArgs}"],
"cwd": "${cmake.testWorkingDirectory}"
}
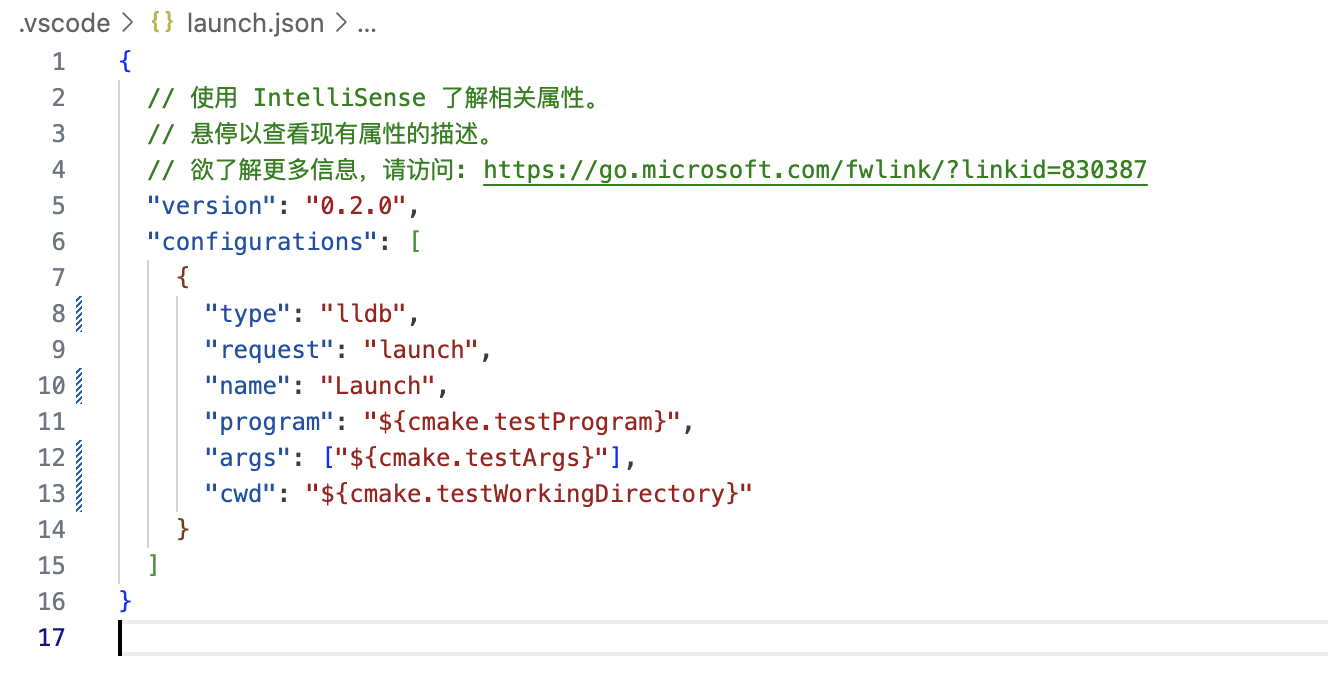 3. 打上断点,在
3. 打上断点,在 测试
插件中对单个测例进行单步调试 
实验一¶
1.在 task1 中存在部分 Loc 要求输出相对路径,部分 Loc 要求输出绝对路径,是否需要针对不同要求编写不同方式的 print_token?¶

 答:相对路径与绝对路径的区别并不是 print_token()函数导致的,而是由于 clang 预处理时输出格式不同所导致的(详见 task0-answer 生成的预处理源代码,路径为 build/test/task0/*),词法规则中对预处理信息的处理可以提供文件路径信息,可以关注预处理信息中的最后一条。
答:相对路径与绝对路径的区别并不是 print_token()函数导致的,而是由于 clang 预处理时输出格式不同所导致的(详见 task0-answer 生成的预处理源代码,路径为 build/test/task0/*),词法规则中对预处理信息的处理可以提供文件路径信息,可以关注预处理信息中的最后一条。
2.预处理文件中没有关于源文件的行号信息,如何识别出词法单元出现在源文件中的位置?是否需要额外编写脚本?¶
答:关于源文件的行号信息,需要从预处理文件中的预处理信息中获取,无需额外编写脚本
例如#
1 "./basic/000_main.sysu.c"
2:其中'#'右边的数字 1 即下一行有效内容出现在对应源文件中的行数(可自行比对预处理后的源文件与标准输出 answer.txt),此后的行号/列号信息需要自行维护
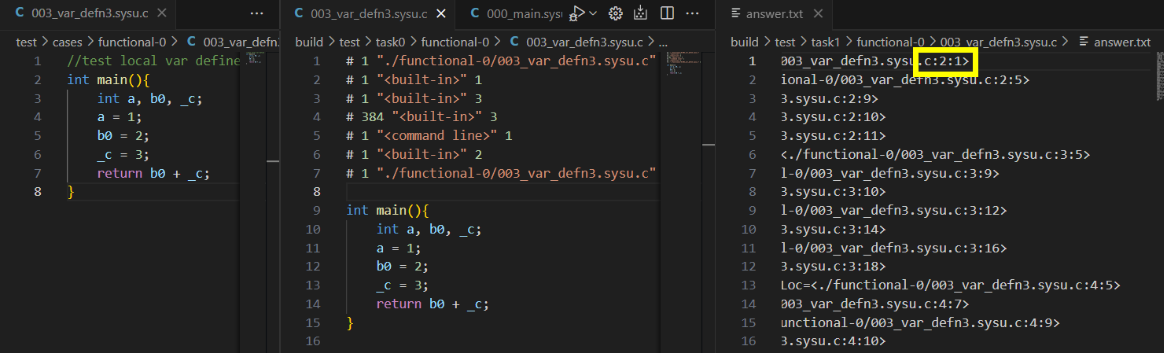
如图是 003 样例的源文件,预处理文件和答案,起始行并不是 1
3.词法单元出现在源文件中的位置和源文件的路径需要输出吗?¶
答:除 EOF 和不可见字符外,需要输出其他所有词法单元在源文件的位置和源文件的路径
4.如何理解预处理信息?¶
问题描述:为什么预处理信息中有多个地址,我选取哪一个?是最后一个吗?
为什么下图中 answer 中第一个 void 是第十行?是因为第九行的#号后面的 10 吗?为什么不采用第一行或者第八行#后的 1 呢?
地址后面跟着的数字是什么意思?是为了干扰预处理吗?需要提取出来用在哪里吗?
答:
- 预处理信息应选取最后一个地址
- 因为在"sylib.h"头文件中,"void _sysy_starttime..."为第 10 行;预处理信息第九行的意思是下一行的词法单元处于源文件中的行号
- 地址后的数字与输出无关,可忽略
实验二¶
注:在同学们阅读此部分文档时,请区分解答是涉及 antlr 框架,还是 bison 框架,以免造成误解。
1.为什么 g4 文法可以用 unary_expression : postfix_expression | unary_operator unary_expression; 而不能用 (unary_operator)* postfix_expression ?¶
在解释这个问题前,需要说明如下事项。在 task2 中,我们既可以使用“递归”的文法,也可以使用“直接”的文法。例如 expression 的这两种写法都是可以的:
assignment_expression | expression Comma assignment_expression
assignment_expression (Comma assignment_expression)*
但是在 task2 中,需要注意,你的 g4 的文法会影响 ctx->assignment_expression()
的返回类型:
文法是 assignment_expression | expression Comma assignment_expression 时,
ctx->assignment_expression() 是单个的指针;
文法是 assignment_expression (Comma assignment_expression)* 时,
ctx->assignment_expression() 是一个 vector,里面存放一堆指针。
怎么回事呢?这是因为助教们的脚本会根据你的文法,在 SYsUParser.h 中自动生成相应的类型。
比如
assignment_expression (Comma assignment_expression)*,因为里面 assignment_expression 的数量是不确定的,所以需要用 vector,
ctx->assignment_expression()
便是一个 vector,与此同时,expression 将会有许多的孩子分支,
auto children = ctx->children; 之后, children[0]、 children[2]、
children[4] ...便对应各个 assignment_expression 节点。
另一个例子,
assignment_expression | expression Comma assignment_expression,里面 assignment_expression 的数量是确定的 1,于是
ctx->assignment_expression()
便是单个的指针,与此同时,expression 的孩子分支要么只有一个,要么有三个(跟你写的文法是呼应的)。
现在回到标题的问题,为什么一元表达式不能用非递归型的
(unary_operator)* postfix_expression
呢?这其实是助教的问题,因为助教在一些已实现的代码里,是按照
ctx->unary_operator() 是单个的指针写的代码,但是如果你把文法改成
(unary_operator)* postfix_expression,就会使得 ctx->unary_operator()
变成一个 vector 了,于是助教们写的代码会炸。
就结果而言,对一元表达式,建议使用“递归”的文法
unary_expression : postfix_expression | unary_operator unary_expression;。当然对于其他大多数文法规则,你用“递归”的文法或者“直接”的文法都可以!注意一下上述的“是否是 vector”的问题即可。
2.关于 children[i] 与 ctx->assignment_expression() 的区别¶
以文法 expression : assignment_expression (Comma assignment_expression)* ;
为例,
auto children = ctx->children;
for(int i=0;i<children.size();i+=2)children[i];
这样取出的偶数位置的 children[i] 便对应各个 assignment_expression
节点,但需注意类型转换,因为 children[i] 还不是
ast::Assignment_expressionContext* 类型,照葫芦画瓢可以写出类似的代码:
node->rht = self(dynamic_cast<ast::Assignment_expressionContext*>(children[i]));
这里稍微介绍一下这个 self 是做什么的:
在 task2 中,你会用到大量的
make<???>(),这个 make 函数的功能是向系统申请一小块内存空间,然后返回一个指向该实空间的指针,例如
auto ret = make<CallExpr>();。
我们的函数诸如
Expr* Ast2Asg::operator()(ast::Postfix_expressionContext* ctx),返回的便是这个 ret 指针,但重点是这个 ret 指针指向了一个实空间,这个实空间正是我们通过调用
make<???>() 申请得到的。
我们用到的许多 self 就是诸如
Expr* Ast2Asg::operator()(ast::Postfix_expressionContext* ctx)
的函数中的某一种。总之, self(???)
返回一个指针,但具有实际价值的,是这个指针指向的实空间。
回归正题,介绍完 children[i],再来介绍 ctx->assignment_expression()。
调用
auto list=ctx->assignment_expression(),返回一个 vector,list 里面便装着一堆
assignment_expression。通过 for(int i = 0; i < list.size(); i++)list[i];
可以访问 expression 的每一个 assignment_expression
孩子。注意我们不需要像 children 那样访问 0、2、4、6 这样的位置,因为
ctx->assignment_expression() 返回一个 vector,里面只装了
assignment_expression,而不会装有 Comma。
在编写代码时,需注意 list[i] 和 self(list[i]) 的区别。前文已提到了
self(???) 的作用, self(???)
实际上会调用我们写的那些函数,返回一个指针,这个指针指向一个 make 出来的实空间。而
list[i]
仅是在遍历 ctx 的孩子。我们的 task2 要做的就是让指针们指向正确的 make 出来的实空间,这个实空间往往也具备一些指针成员,指向其他的实空间。这样指来指去,把实空间和指针安排好后,就构建好了 asg 语法图。
3.关于函数定义的若干问题¶
一种能够减少你的工作量的 g4 文法如下:
parameter_list
: parameter_declaration (Comma parameter_declaration)*
;
parameter_declaration//参数列表可能出现右侧的情况: int a 或 int b[] 或 int 或 int c=3 , 不过本次实验不会出现int c=3这样带默认参数值的测试任务
: declaration_specifiers declarator?
;
function_definition
//在实际的完整C语法中,文法会显得错综复杂
//而对于我们初学者来说,使用下面这行文法更好理解,同时也更切合我们的实验任务
//因为这种简单的实现方法将函数定义与变量定义分离,不会像完整C语法那样需要向下识别若干个分支才能判定那是一个函数定义
: declaration_specifiers direct_declarator LeftParen parameter_list? RightParen ( compound_statement | Semi )
;
为了便于后文你理解“类型”与“限定”,此处稍作提及。
你可能在代码中见过一个叫 specs 的变量,是 SpecQual 类型。 SpecQual
类型包含“类型 spec”与“是否限定 qual”两项内容。
下文的函数定义的代码中含有详细的注释解析,可以帮助你理解这部分具有复杂层次的内容,代码仅供参考,同学们也可以有其他实现方式。
FunctionDecl*
Ast2Asg::operator()(ast::Function_definitionContext* ctx){
auto ret = make<FunctionDecl>();
mCurrentFunc = ret;
auto type = make<Type>();
ret->type = type;
auto sq = self(ctx->declaration_specifiers());
type->spec = sq.first, type->qual = sq.second;
auto [texp, name] = self(ctx->direct_declarator(), nullptr);//右侧调用的函数为 std::pair<TypeExpr*, std::string> Ast2Asg::operator()(ast::Direct_declaratorContext* ctx, TypeExpr* sub)
//这里解释一下texp的类型,即TypeExpr*,你可以简单认为他是处理数组定义的,例如对于int a[5][3],TypeExpr*负责记录这些维度的长度
//那么texp作为一个指针类型,即TypeExpr*类型,这个指针若非空,是要指向一个实空间的,一个例子便是指向 make<ArrayType>(); 的实空间
//按Ctrl点开 ArrayType 跳转到定义,发现struct ArrayType : TypeExpr{
//TypeExpr作为父亲类有一个指针成员sub,而ArrayType作为儿子类有一个int类型
//当然ArrayType是继承了父亲类的,可以认为ArrayType有一个指针成员sub有一个int类型一共两项内容。
//于是texp这个TypeExpr*类型可以指向一个ArrayType;
//这个ArrayType的int成员记录下第一维的长度5(用上文的例子)、sub成员则指向另一个ArrayType(用于记录第二维度的长度3)
//实际上这就是一个链表结构,你可以从右侧这个函数一窥这个“链表”是怎么造出来的 std::pair<TypeExpr*, std::string> Ast2Asg::operator()(ast::Direct_declaratorContext* ctx, TypeExpr* sub)
auto funcType = make<FunctionType>();
funcType->sub = texp;
type->texp = funcType;
ret->name = std::move(name);
//观察代码,发现有三层结构,
//auto ret = make<FunctionDecl>();
//auto type = make<Type>();
//auto funcType = make<FunctionType>();
//其中ret明显是完整描述整个函数的,type则由type->spec type->qual可以看出来有限定的功能(例如Const)
//此外按照type的意义,实际上这个type能够完整描述除了实际取值外,该函数的所有【返回类型、参数类型】,但是不知道参数名字,例如函数int a[2][4](int b,char c[3]);那么只看type就能知道返回一个int[2][4],参数是int ,char [3]
//由于type的make<Type>()类型不能带参数列表,因此type通过type->texp=funcType指向了它的代理人,让代理人来存放参数列表
//funcType作为type的代理人,它有两项内容,参数列表params以及TypeExpr*指针sub,我们还是用函数int a[2][4](int b,char c[3]);的例子
//funcType的sub用来存放[2][4],参数列表params第一项存放int ,第二项存放char [3]
//ret存放函数名name,函数实现body,以及一个参数列表(含有参数名字)
//注:我们不考虑int a[2][4](int b=10,char c[3]);这种带默认值的
Symtbl localDecls(self);
if(auto plist = ctx->parameter_list()){
for (auto&& param : plist->parameter_declaration()) {
auto paramDecl = self(param);//param的实空间是make<VarDecl>()
funcType->params.push_back(paramDecl->type);
ret->params.push_back(paramDecl);
localDecls[paramDecl->name] = paramDecl;//本地符号表,保存当前作用域的所有声明
}
}
//将函数定义加入符号表,以允许递归调用
//当函数定义未加入符号表时,调用 self(ctx->compound_statement()) 会炸,
//例如归并排序msort的函数实现本身就带有递归自调用msort,此时 self(ctx->compound_statement()) 在内部识别到 msort(l,r) 而生成一个 make<CallExpr> 节点,
//但由于函数名未加入符号表,于是助教们写的代码给你 ABORT(); 了
if(((*mSymtbl)[ret->name])==nullptr){
(*mSymtbl)[ret->name] = ret;
if(ctx->compound_statement())
ret->body = self(ctx->compound_statement());
}
else{//有时也会重定义,这时我们可以保留那种带有ret->body的函数声明
if(ctx->compound_statement()){
(*mSymtbl)[ret->name] = ret;
ret->body = self(ctx->compound_statement());
}
}
return ret;
}
持续更新中
YatCC Agent