使用 ANTLR 完成 Task2¶
任务介绍¶
在本次实验中,在本次实验中,同学们需要完成以下任务:
- 词法分析:补充词法分析器缺失的部分。
- 补全
SYsULexer.tokens,使其包含测试用例涉及的所有 token 种类。在构建项目时,SYsULexer.py脚本会根据SYsULexer.tokens生成SYsULexer.tokens.hpp,来为SYsULexer.cpp提供一些k开头的 token 类型定义。 -
补全
SYsULexer.cpp中的kClangTokens,实现 Clang 风格的 token 名到k开头的 token 名之间的映射。 -
正式工作:补充缺失的文法规则和语义动作,实现语法分析器与从 AST 到 ASG 的转换。其中
SYsUParser.g4用于定义构建 AST 的文法规则,Ast2Asg.cpp用于将antlr匹配得到的 AST 转换为 ASG。注意SYsUParser.g4与Ast2Asg.hpp/cpp需要同步更改:在SYsUParser.g4中修改了已有的规则就需要在Ast2Asg.hpp/cpp中对应的处理函数处做修改;如果在SYsUParser.g4中添加了新的规则就需要在Ast2Asg.cpp中添加新的处理函数,以保证 AST 能够正确转换为 ASG。实现Ast2Asg.cpp的逻辑时,需要遵循asg.hpp中对 ASG 的定义。因此同学们需要认真阅读并理解asg.hpp。
接下来会先向大家讲解最基本的知识,并且在“上手思路”一节中手把手教大家完成本实验的方式。经过“上手思路”的培训后,同学们就可以尽情探索本实验的后续文档和内容了~
这些代码使用 antlr 实现了一个简单的语法分析器,用于将 SYsU_lang
语言的源代码转换为抽象语法树(AST),再进一步转换为抽象语法图(ASG),最后再将 ASG 转换为 JSON 格式进行输出。
(将 ASG 转换为 JSON 格式输出的原因是 ASG 是存在于内存中的不便于阅读的数据结构,输出为 JSON 格式方便同学们与实验标准答案对应的输出进行对比差错。)
简单来说,根据本实验的流程图,这些代码可分为 5 个部分:
- 前缀为
SYsULexer的四个文件是本实验的词法分析器部分; SYsUParser.g4定义了本实验的抽象语法树 AST;Ast2Asg类用于将 AST 转换为 ASG;Typing类用于对 ASG 进行类型推导和检查;Asg2Json类用于将 ASG 转换为 JSON 格式。
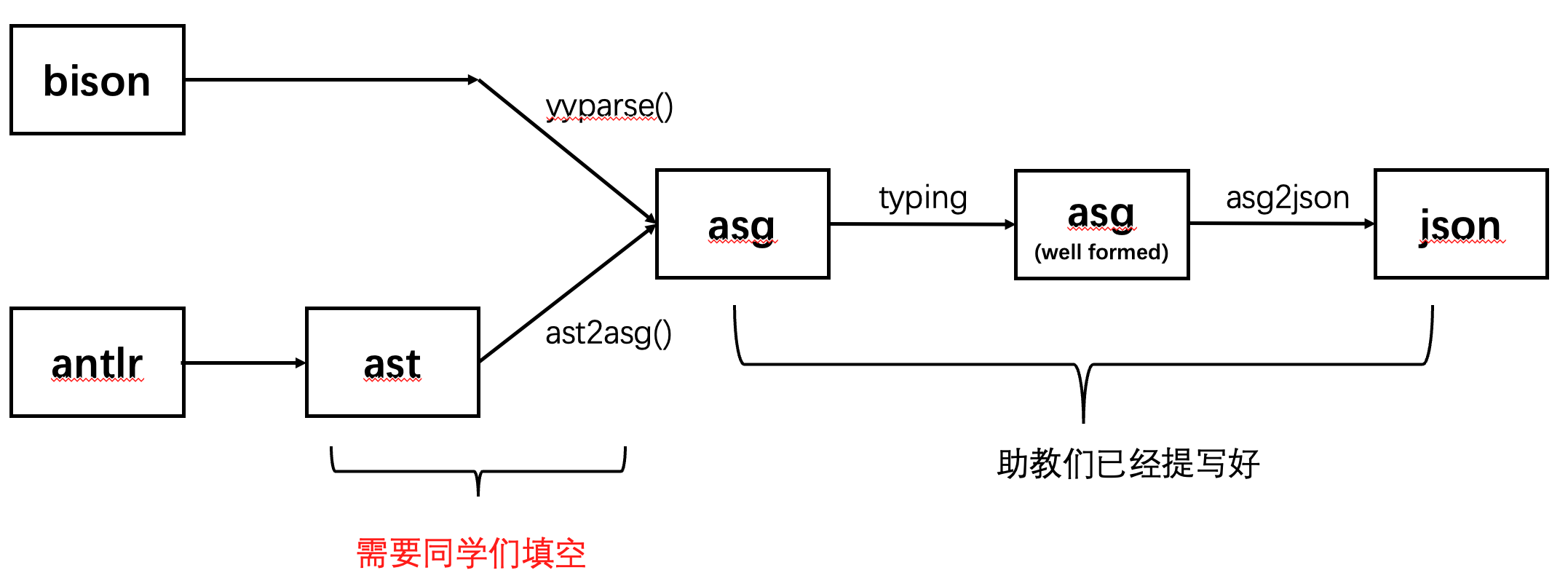
不过在本实验中,除了词法分析器部分的前置工作,同学们只需要修改 SYsUParser.g4
和 Ast2Asg.cpp/hpp 这两个部分即可。
同学们只需要编辑 SYsUParser.g4 以定义抽象语法树 AST(以 g4 为后缀名的文件 是
antlr
中用于定义词法规则和语法规则的文件)。这是完成语法分析器所需的唯一工作,除此之外这个语法分析器的其它工作已经由助教们预先在
main.cpp
中实现了。(感兴趣的同学可以自行借助“Task2 的程序做了什么”一节深入了解)
当然,本实验不会如此简单。在本实验中同学们需要将 AST 转换为 ASG 以获得额外的语义信息,为此同学们还需要完成
Ast2Asg.cpp/hpp 的填写。在这个过程中,同学们需要重点关注 asg.hpp,因为
asg.hpp 定义了本实验的 ASG 结构。只有弄懂了 ASG 的结构,才能正确填写
Ast2Asg.cpp/hpp 。
代码说明¶
实验文件的整体结构如下所示:
antlr/
├── Ast2Asg.cpp # 需要修改
├── Ast2Asg.hpp # 需要修改
├── CMakeLists.txt
├── SYsULexer.cpp # 需要修改
├── SYsULexer.hpp
├── SYsULexer.py
├── SYsULexer.tokens # 需要修改
├── SYsUParser.g4 # 需要修改
├── main.cpp
common/
├── Asg2Json.cpp
├── Asg2Json.hpp
├── Typing.cpp
├── Typing.hpp
└── asg.hpp
其中 common/ 文件夹包含了一系列公用代码,在
公用代码介绍 中已经详细介绍过了。
antlr/ 则是使用 ANTLR 完成实验会涉及到的代码,接下来在各个小节详细介绍。
主程序部分¶
main.cpp 是整个语法分析器程序的入口。
main.cpp 中,首先用 inFile 初始化一个 ANTLRInputStream 实例
input,然后用 input 初始化一个 SYsULexer 实例 lexer。接着,我们用
lexer 初始化一个 token 流对象 tokens,再用 tokens 初始化一个 SYsUParser
实例 parser。最后,只需要调用 parser 的 compilationUnit()
方法,就得到了 AST。
antlr4::ANTLRInputStream input(inFile);
SYsULexer lexer(&input);
antlr4::CommonTokenStream tokens(&lexer);
SYsUParser parser(&tokens);
auto ast = parser.compilationUnit();
其中的 SYsULexer 类定义在 SYsULexer.hpp 中,这是一个继承自
antlr4::TokenSource 的类,主要作用是从输入流中读取字符,并将其解析为词法标记(
antlr4::Token)供解析器使用。
SYsUParser 类则是来自 ANTLR 根据 SYsUParser.g4 生成的,你可以在
/build/antlr4_generated_src/task2-antlr/SYsUParser.h
中找到它的详细定义定义。这个类负责根据词法分析器生成的 token 流进行语法分析,并构建出 AST。
SYsUParser 这个名字则来源于 SYsUParser.g4 开头的定义:
parser grammar SYsUParser;
options {
tokenVocab=SYsULexer;
}
这里的 options 指定该解析器语法文件使用 SYsULexer 的词汇表。
得到 AST 之后, main.cpp 创建了一个 Ast2Asg
实例,用于将 AST 转换为 ASG。对于包含着语义信息的 ASG,我们无法确保 ASG 的语义合法性,因此还需要通过
Typing 类对 ASG 中的节点执行类型检查与推导:
Obj::Mgr mgr;
asg::Ast2Asg ast2asg(mgr);
auto asg = ast2asg(ast->translationUnit());
mgr.mRoot = asg;
mgr.gc();
asg::Typing inferType(mgr);
inferType(asg);
mgr.gc();
asg::Asg2Json asg2json;
llvm::json::Value json = asg2json(asg);
最后,由于 AST 和 ASG 作为类树类图的数据结构,都不是易于打印输出的结构,因此
main.cpp 创建了一个 Asg2Json
实例,将 ASG 转换为 JSON 格式的数据,再输出到指定的路径中。
asg::Asg2Json asg2json;
llvm::json::Value json = asg2json(asg);
outFile << json << '\n';
词法分析部分¶
词法分析部分包括以 SYsULexer 开头的几个文件。
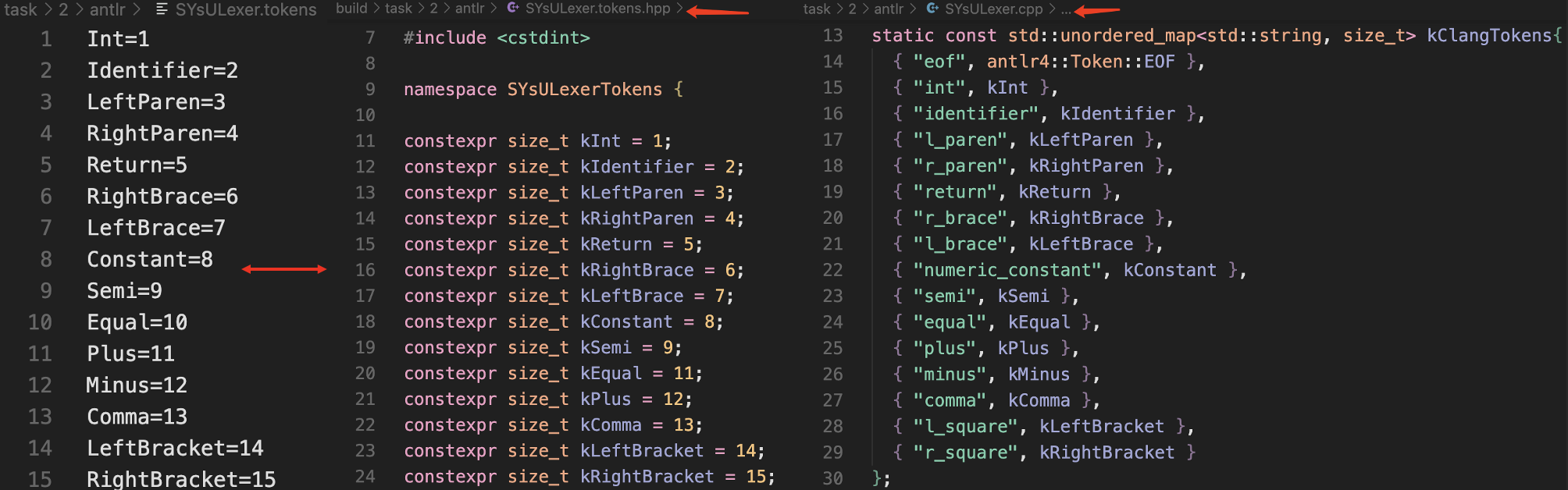
同学们需要先补全 SYsULexer.tokens,使其包含测试样例中涉及的所有 token
名字。在构建项目时, SYsULexer.py 会根据 SYsULexer.tokens 来生成
SYsULexer.tokens.hpp,来为 SYsULexer.cpp 提供一些 k 字母开头的
constexper 定义。然后同学们需要补全 SYsULexer.cpp 中的
kClangTokens,实现 Clang 风格的 token 名到 k 开头的 token 名之间的映射。
例如,你在 SYsULexer.tokens 中添加了 Int=1, SYsULexer.py 会在
SYsULexer.tokens.hpp 中生成一个 constexpr size_t kInt = 1;
的定义。由于 Clang 的 toke 名可能与你定义的不同,所以你需要给 SYsULexer.cpp
中的 kClangTokens 添加一个映射 {"Int", kInt}。
生成 AST 部分¶
.g4
文件是 ANTLR 中用于定义词法规则和语法规则的文件。ANTLR 规定,以大写字母开头定义的语句用于定义词法规则,以小写字母开头定义的语句用于定义语法规则。
ANTLR 根据 SYsUParser.g4 生成 Context
类,里面会有若干子节点函数,这些子节点函数会根据子节点的出现模式来返回不同的子节点数据结构。
以 initDeclaratorList 节点为例,可能同时存在多个相同的子节点
initDeclarator:
initializerList
: initializer (Comma initializer)*
;
则 ANTLR 为其生成的子节点函数 p->initDeclarator() 会返回一个 std::vector
类型的数组。因此在下面的代码中我们可以发现,我们需要遍历这个 vector 来获取每个
initDeclarator 子节点:
std::vector<Decl*>
Ast2Asg::operator()(ast::DeclarationContext* ctx)
{
std::vector<Decl*> ret;
auto specs = self(ctx->declarationSpecifiers());
if (auto p = ctx->initDeclaratorList()) {
for (auto&& j : p->initDeclarator())
ret.push_back(self(j, specs));
}
// 如果 initDeclaratorList 为空则这行声明语句无意义
return ret;
}
另一种情况,在以 unaryExpression
节点为例的节点中,不可能存在超过一个同类型子节点, unaryExpression
的三类子节点不论是 postfixExpression、 unarOperator 还是构成了右递归的
unaryExpression,都不可能同时存在超过一个:
unaryExpression
: postfixExpression
| unaryOperator unaryExpression
;
对于这类节点,ANTLR 为其生成的子节点函数会直接返回子节点本身而非 std::vector
或其它类型的容器:
Expr*
Ast2Asg::operator()(ast::UnaryExpressionContext* ctx)
{
\\ ...
ret->sub = self(ctx->unaryExpression());
return ret;
}
对于其它更多情况,同学们想可以阅读
/YatCC/build/antlr4_generated_src/task2-antlr/SYsUParser.h 文件,深入研究。
转换到 ASG 部分¶
Ast2Asg.cpp 和 Ast2Asg.hpp 中的 Ast2Asg
类负责将 AST 转换为 ASG,其中包括对各种语法结构(如表达式、语句、声明等)的处理方法。
相关的代码在 main.cpp 中是像下面这样被调用的:
asg::Obj::Mgr mgr;
asg::Ast2Asg ast2asg(mgr);
auto asg = ast2asg(ast->translationUnit());
首先,代码创建了 Ast2Asg 类的一个实例 ast2asg,并将对象管理器
mgr(负责在 AST 到 ASG 的转换过程中创建和管理所有 ASG 节点的生命周期)作为构造函数的参数传递给它。
然后,代码调用了 ast2asg 的 ()
运算符重载,传入了由 ANTLR 生成的 AST 的根节点——通常是代表整个程序的
translationUnit
节点。这个函数从根节点开始遍历 AST,为 AST 节点创建相应的 ASG 节点,并根据 AST 节点之间的关系构建 ASG 的结构,具体来说:
- 遍历 AST:AST 是根据源代码的语法结构自顶向下递归构建的树形结构,每个节点代表了源代码中的一个语法结构(如表达式、语句、声明等)。函数首先遍历 AST 的每个节点。
- 节点转换:对于 AST 的每个节点,
Ast2Asg类中定义的对应的转换方法会被调用。这些方法负责将 AST 节点转换为 ASG 节点。转换过程中可能会创建新的 ASG 节点对象,并通过对象管理器mgr进行管理。 - 构建 ASG 结构:在转换各个 AST 节点的同时,转换方法还会根据 AST 节点之间的父子关系和兄弟关系来构建 ASG 的图结构。这一步骤确保了转换后的 ASG 能够准确反映程序的逻辑结构和语法结构。
- 返回 ASG 的根节点:整个转换过程完成后,会返回转换后的 ASG 的根节点。这个根节点就代表了整个程序的 ASG(的入口),也是后续编译过程中进行语义分析、优化和代码生成等操作的基础。
这个“根据 AST 节点之间的关系构建 ASG 的结构”的过程,需要同学们通过不断修改完善
Ast2Asg 类来完成。
上手思路¶
接下来,我们以一个具体的例子,来向大家说明完成实验的大致流程。
如果同学们还没做任何修改的情况下,直接运行评分脚本,会看到很多样例没有拿到满分。例如
/YatCC-P/build/test/task0/functional-1/017-xxx 到
/YatCC-P/build/test/task0/functional-1/022-xxx
这几个样例,使用了我们尚未实现的语法规则。目前的语法分析器还不能处理像下面这样的简单二元运算:
a * 5
a / b
a / 5
a / 3
a % 3
所以我们接下来的目标,就是实现对乘法、除法和取模运算的支持。
修改语法规则¶
如果同学们还没有对 SYsUParser.g4
进行过任何修改,那其中关于表达式的规则目前是这样的:
postfixExpression
: primaryExpression
;
unaryExpression
:
(postfixExpression
| unaryOperator unaryExpression
)
;
unaryOperator
: Plus | Minus
;
additiveExpression
: unaryExpression ((Plus|Minus) unaryExpression)*
;
众所周知,运算之间有优先级关系,我们怎样编写语法规则才能“先匹配乘法,再匹配加法”呢?同学们可以查看 文法参考 部分,其中是这样写的:
unary_expression
: postfix_expression
| INC_OP unary_expression
| DEC_OP unary_expression
| unary_operator cast_expression
| SIZEOF unary_expression
| SIZEOF '(' type_name ')'
;
cast_expression
: unary_expression
| '(' type_name ')' cast_expression
;
multiplicative_expression
: cast_expression
| multiplicative_expression '*' cast_expression
| multiplicative_expression '/' cast_expression
| multiplicative_expression '%' cast_expression
;
additive_expression
: multiplicative_expression
| additive_expression '+' multiplicative_expression
| additive_expression '-' multiplicative_expression
;
可以发现,这几个规则之间有“嵌套关系”,例如关于 additive_expression
的规则中,包含
multiplicative_expression。通过嵌套产生式,语法分析器能够按照优先级正确解析表达式。对于上面这段规则,同学们可以直观地理解:从上到下,匹配的优先级依次降低。
高优先级的运算符(更一般地说,高优先级的匹配规则)应该位于更深层次的产生式中,确保它们优先被解析。这是因为对于语法树而言,“越浅”意味着越接近开始符号,“越深”意味着越接近输入串,会先被规约。
模仿参考文法,我们可以在 .g4 文件中这样写:
multiplicativeExpression
: unaryExpression ((Star|Div|Mod) unaryExpression)*
;
additiveExpression
: multiplicativeExpression ((Plus|Minus) multiplicativeExpression)*
;
注意 multiplicativeExpression 中 ((Star|Div|Mod) unaryExpression)* 带了一个
* 表示可以出现 0 次或无数次,也就相当于:
multiplicativeExpression
: unaryExpression
| multiplicativeExpression (Star|Div|Mod) unaryExpression
;
添加处理函数¶
在 SYsUParser.g4 中修改了已有的规则就需要在 Ast2Asg.cpp
中对应的处理函数处做修改;在 SYsUParser.g4 中添加了新的规则,就需要在
Ast2Asg.cpp 中添加新的处理函数。
我们刚才修改了 additiveExpression,需要找到对应的 () 重载,但是又这么多 ()
重载,怎么找呢?同学们应该知道,C++中“函数名+函数参数列表”唯一确定一个函数。这里“函数名”是相同的,我们可以通过传入参数来找到想要的函数。在这里,对于
additiveExpression,参数应该是一个 AdditiveExpressionContext*
类型的指针,所以可以找到函数如下:
Expr*
Ast2Asg::operator()(ast::AdditiveExpressionContext* ctx)
{
auto children = ctx->children;
Expr* ret = self(dynamic_cast<ast::UnaryExpressionContext*>(children[0]));
for (unsigned i = 1; i < children.size(); ++i) {
auto node = make<BinaryExpr>();
auto token = dynamic_cast<antlr4::tree::TerminalNode*>(children[i])
->getSymbol()
->getType();
switch (token) {
case ast::Plus:
node->op = node->kAdd;
break;
case ast::Minus:
node->op = node->kSub;
break;
default:
ABORT();
}
node->lft = ret;
node->rht = self(dynamic_cast<ast::UnaryExpressionContext*>(children[++i]));
ret = node;
}
return ret;
}
ast::AdditiveExpressionContext 是 ANTLR 自动生成的变量类型,你可以在
build/antlr4_generated_src/task2-antlr/SYsUParser.h
中找到它的定义。类似的,还有 ast::MultiplicativeExpressionContext,它们都是
antlr4::ParserRuleContext
的子类,表示识别到这里时的上下文信息,也可以理解为一个 AST 节点。
利用 ctx->children
可以获取到当前加法表达式上下文节点的所有子节点。在 ANTLR 生成的语法分析树中,每个节点可能有多个子节点,它们代表了该表达式的组成部分(例如,在表达式
a + b 中, a、 + 和 b 是子节点)。由于我们的规则中有
*,子节点的数量不确定,可能有很多个,所以代码中先用 children[0] 获取
unaryExpression,然后用循环尝试处理剩下的部分。
循环体内:
- 首先创建了一个新的
BinaryExpr对象node,它表示一个二元表达式节点。BinaryExpr类型定义在common/asg.hpp中,同学们在实验过程中,一定要仔细阅读这个文件,了解不同的 AST 节点及其成员,以便编写处理函数。 - 接下来,通过
dynamic_cast将当前子节点转换为antlr4::tree::TerminalNode类型,以便获取其对应的 token 类型。然后通过switch语句判断 token 的类型,并根据不同的 token 类型设置node->op的值。 - 递归调用
self()方法来处理下一个子节点,并将其设置为node的右子节点。最后,将node赋值给ret,以便在下一次循环中使用。重复这个过程,直到所有子节点都被处理完毕。
对于表达式
a+b-c+d,下面这个表格,展示了循环过程中各个变量的值,来帮助大家理解这个函数的执行过程:
| i | ret | token | node->lft | node->rht |
|---|---|---|---|---|
| 1 | a | |||
| + | a | b | ||
| 2 | a+b | |||
| - | a+b | c | ||
| 3 | a+b-c | |||
| + | a+b-c | d | ||
| a+b-c+d |
介绍完同学们拿到的代码中的
Expr* Ast2Asg::operator()(ast::AdditiveExpressionContext* ctx)
函数之后,我们就知道如何为 SYsUParser.g4 中的新规则添加新的 Ast2Asg.cpp
的处理函数了。
根据我们对规则的修改,这个函数应该被修改为:
Expr*
Ast2Asg::operator()(ast::AdditiveExpressionContext* ctx)
{
auto children = ctx->children;
// assert(dynamic_cast<ast::UnaryExpressionContext*>(children[0]));
Expr* ret =self(dynamic_cast<ast::MultiplicativeExpressionContext*>(children[0]));
for (unsigned i = 1; i < children.size(); ++i) {
auto node = make<BinaryExpr>();
auto token = dynamic_cast<antlr4::tree::TerminalNode*>(children[i])
->getSymbol()
->getType();
switch (token) {
case ast::Plus:
node->op = node->kAdd;
break;
case ast::Minus:
node->op = node->kSub;
break;
default:
ABORT();
}
node->lft = ret;
node->rht =
self(dynamic_cast<ast::MultiplicativeExpressionContext*>(children[++i]));
ret = node;
}
return ret;
}
我们刚才还添加了关于 multiplicativeExpression 的新规则,所以类似的,需要在
Ast2Asg.cpp 添加一个新的处理函数:
Expr*
Ast2Asg::operator()(ast::MultiplicativeExpressionContext* ctx)
{
auto children = ctx->children;
Expr* ret = self(dynamic_cast<ast::UnaryExpressionContext*>(children[0]));
for (unsigned i = 1; i < children.size(); ++i) {
auto node = make<BinaryExpr>();
auto token = dynamic_cast<antlr4::tree::TerminalNode*>(children[i])
->getSymbol()
->getType();
switch (token) {
case ast::Star:
node->op = node->kMul;
break;
case ast::Div:
node->op = node->kDiv;
break;
case ast::Mod:
node->op = node->kMod;
break;
default:
ABORT();
}
node->lft = ret;
node->rht = self(dynamic_cast<ast::UnaryExpressionContext*>(children[++i]));
ret = node;
}
return ret;
}
不要忘记在 Ast2Asg.hpp 中添加新函数的声明:
Expr* operator()(ast::MultiplicativeExpressionContext* ctx);
补充说明¶
刚才提到,同学们要仔细阅读 asg.hpp。下面展示了 asg.hpp
的主体结构,其中不同种类的结构体就代表着不同种类的节点,我们在公用代码介绍部分已经提到过了。如果看完上面的注释,对某个结构体的含义还是不太清楚,可以查看
asg2json.cpp 中该结构体的的打印方式。
asg.hpp
中定义了所有会使用到的结构体,而且该文件无需同学们修改。所以同学们还可以据此文件推断,究竟需要哪些产生式/文法规则。再次强调,同学们需要仔细阅读
asg.hpp,加深对结构体的含义的理解,避免低级错误。
namespace asg {
//==============================================================================
// 类型
//==============================================================================
struct Type : Obj; /* 用于表示节点的类型,包括基本类型和复合类型 */
struct TypeExpr : Obj; /* 表示更复杂的类型,如数组和函数 */
struct PointerType : TypeExpr;
struct ArrayType : TypeExpr;
struct FunctionType : TypeExpr;
//==============================================================================
// 表达式
//==============================================================================
struct Expr : Obj; /* 所有表达式节点的基类,比如字面量、二元运算、函数调用等 */
struct IntegerLiteral : Expr;
struct StringLiteral : Expr;
struct DeclRefExpr : Expr; /* 声明引用表达式 */
struct ParenExpr : Expr; /* 带括号的表达式 */
struct UnaryExpr : Expr; /* 一元表达式 */
struct BinaryExpr : Expr; /* 二元表达式 */
struct CallExpr : Expr; /* 函数调表达式 */
struct InitListExpr : Expr; /* 初始化列表(如数组或结构体初始化) */
struct ImplicitInitExpr : Expr; /* 隐式初始化的表达式 */
struct ImplicitCastExpr : Expr; /* 隐式类型转换表达式 */
//==============================================================================
// 语句
//==============================================================================
struct Stmt : Obj /* 所有语句的基类,例如表达式语句和符合语句 */
struct NullStmt : Stmt /* 空语句 */
struct DeclStmt : Stmt /* 声明语句 */
struct ExprStmt : Stmt /* 表达式语句 */
struct CompoundStmt : Stmt /* 复合语句(大括号包围的语句块) */
struct IfStmt : Stmt
struct WhileStmt : Stmt
struct DoStmt : Stmt
struct BreakStmt : Stmt
struct ContinueStmt : Stmt
struct ReturnStmt : Stmt
//==============================================================================
// 声明
//==============================================================================
struct Decl : Obj /* 所有声明的基类,例如变量声明和函数声明 */
struct VarDecl : Decl /* 变量声明 */
struct FunctionDecl : Decl /* 函数声明 */
//==============================================================================
// 顶层
//==============================================================================
struct TranslationUnit : Obj /* 代表整个程序或一个编译单元,是ASG的根节点 */
} // namespace asg
YatCC Agent