优化算法
本节中,将给出部分优化算法的示例和原理介绍。碍于篇幅,此处仅提供算法实现的效果展示和简单的原理说明,同学可以通过其他方式自行查找更多的资料,或者参考 LLVM 官方 Github 仓库的 优化实现。
同时,我们还提供一个简化的仿 LLVM 的 优化实现。该实现用的 IR 数据结构是一套仿 LLVM 的自定义结构。同学们可以参考该实现来实现 LLVM 版本的优化算法。
本实验的测例名就直白的显示了对应的优化方法,同学们可以根据当前的测例分数,选择分数较低的测例对应的优化方法进行实现。根据实现难度和优化效果,可以参考以下实现顺序:
- 强度削弱
- 常量传播
- 死代码消除
- 公共子表达式消除
- 指令合并
- ...
注意,各 Pass 可以被多次调用,也有可能多种 Pass 结合在一起才能有显著的优化效果。同学们在实现过程中,不用一开始就考虑很“通用”,能覆盖所有情况的实现。可以仅仅针对文档中介绍的那个代码示例,实现一个最简单情况的 Pass,说不定就能取得不错的效果了。
数据流优化¶
数据流优化通过分析程序中数据的传递和使用方式改进程序性能,主要涉及 LLVM
IR 的 use-def 链的使用。use-def 链描述 LLVM
IR 中变量定义与使用的关系,若变量 x 在 y 的计算中被使用,则存在一条 use 从
y 指向 x,表示在 y 的定义时需要使用到
x。use-def 链能够表示变量之间的依赖关系,在数据流分析中起着至关重要的作用。
int c = a + b;
// 两条use:%add->%0 和 %add->%1
%0 = load i32, ptr %a, align 4
%1 = load i32, ptr %b, align 4
%add = add nsw i32 %0, %1
上面的例子展示了一条加法指令中的 use-def 链。由于加法指令 %add 的定义使用了
%0 和 %1,因此指令 %0 和 %1 作为 %add 的操作数(operand)可以被 %add
通过 use-def 链搜索得到。
常量传播 & 常量折叠¶
代表测例: bitset-*.sysu.c、 fft-*.sysu.c、 if-combine*.sysu.c
难度:★☆☆☆☆
常量传播(Constant Propagation)与常量折叠(Constant Folding)是最常见的常量优化方式,其原理为在编译阶段尽可能减少常量的计算与存储。两者的区别为:
- 常量传播直接用常量替代变量,减少程序的存储和访存开销
- 常量折叠直接将编译阶段能够计算的常量表达式计算出结果,减少程序运行时的计算量
例如,对于下面这段代码:
const int a = 1, b = 2;
int c = a + b;
经过常量传播可以得到:
int c = 1 + 2;
再经过常量折叠可以得到:
int c = 3;
基于 LLVM 提供的 use-def 链,可以很简单地获取使用到某个变量的指令,因此只需要将常变量
const int 的操作数直接替换为常量即可。对于赋初值但未被修改的 int
类型变量,也可以进行上述替换。除此之外,常量传播与常量折叠可以在语法分析和语义分析阶段完成,即把生成
const int 的子图直接替换为 Constant 节点,感兴趣的同学可以了解与实现。
死代码消除¶
代表测例:
难度:★★★☆☆
死代码消除(Dead Code Elimination,DCE)是一种将对全局变量、输出和返回结果无影响(无副作用)的指令删除的优化。
对于一个程序而言,无副作用的指令进行的计算时没有意义的,其计算结果对于外界来说是不可感知的,即使删除也不会对程序的结果产生影响。
例如,对于下面这段代码:
int main() {
int sum = 0;
int j = 0;
for(int i = 0; i < 10; i ++) sum += i;
...
print(j);
return 0;
}
进行 DCE 优化后,可以得到:
int main() {
int j = 0;
print(j);
return 0;
}
激进的 DCE(Aggresive Dead Code Elimination,ADCE)可以通过遍历返回值、输出指令等对外界可能产生影响的指令的 use-def 链来找出所有需要保留的指令,对于不在该链上的所有指令可以删除。上述方法比较激进,有时候可能会产生错误,我们也难以判断一个变量是否可能对外界产生影响(例如函数调用等),因此我们一般使用普通的 DCE 进行优化。
对于 DCE,我们可以遍历每条指令的 use-def 链,如果该 use-def 链上所有端点都没有被使用(即端点的 use 次数为 0),且链中无函数调用与访存,说明该链上的所有计算结果都是无效计算,应该被删除。更高效的方法是对于中间存在函数调用的 use-def 链,判断该函数是否有副作用(对外界产生影响)。若函数无副作用,则能够继续进行上述 use-def 链遍历。这种能够扩大 DCE 的覆盖范围,提供更大的优化空间。
公共子表达式消除¶
代表测例: hoist-*.sysu.c
难度:★★☆☆☆
公共子表达式消除(Common Subexpression Elimination,CSE)是一个非常经典的优化算法,如果一个表达式 E 在计算得到后没有变化,且同时作为多条指令的操作数被使用,那么 E 就称为公共子表达式:
// (a + b) 是 d 和 e 的公共子表达式
int d = a + b - c;
int e = a + b + c;
// CSE 优化后
int tmp = a + b;
int d = tmp - c;
int e = tmp + c;
CSE 本质上就是复用之前已经计算得到的结果,避免重复计算。根据 CSE 的原理可以引出两个问题:
- 如何判断一个表达式 E 是否是公共子表达式?
- 如何判断一个表达式 E 的值在计算后没有变化?
对于上述两个问题,LLVM IR 的设计能够为我们提供很大的帮助。我们知道 LLVM IR 本质上满足静态单赋值(Static Single Assignment,SSA),即对于编号相同的操作数,我们能够保证它们一定相等。
基于此,假设有某条指令 %3 = bin_op %1, %2,其后有一条指令
%6 = bin_op %x, %y,我们可以判断操作数 %x, %y 是否就是
%1, %2。若是,也即后面这条指令就是 %6 = bin_op %1, %2,由 SSA 特性, %3 与
%6 一定相同。因此, %6 = bin_op %1, %2
这条指令可以直接删除,后续指令中的操作数 %6 都可以用 %3 替换。
特别地,对于访存相关的指令,我们难以直接判断相同内存地址的值在不同时间是否相同。如果硬要判断,需要增加访存分析,所以这样的指令我们可以一般保守地选择不删除。对于单个变量的访存分析相对简单,在 LLVM IR 层面可以对非数组变量的冗余 load、store 指令进行消除(对数组变量的 load 和 store,也即对数组进行修改,一定要执行),例如判断 load 指令的 use 数量是否为 0(load 的结果没有被使用到)。
CSE 可以通过简单的搜索实现:对于每一条可能为公共子表达式的指令,遍历其后面一定数量的指令,判断后面是否存在某条指令计算的内容相同。不难证明其时间复杂度为 \(O(kN)\),其中 \(k\) 为指令窗口大小,\(N\) 为指令总数。\(k\) 可以自行定义,指令窗口的大小决定了遍历的范围。窗口越大,判断公共子表达式的范围越大,优化效果越好,但相应地编译时间也会延长。
更高效的方法是使用全局值编号(Global Value Number,GVN)寻找公共子表达式,该算法在此不作介绍,同学们感兴趣可以自行查找资料。
指令合并¶
代表测例: instruction-combining-*.sysu.c
难度:★★★☆☆
指令合并(Instruction Combining)是一种将多条指令合并成一条指令的优化方式。下面是一个简单的例子:
// 指令合并前(假设b变量只在c的计算中用到)
int b = a + 1;
int c = b + 1;
// 指令合并后
int c = a + 2;
对于算术运算而言,指令合并的前提是存在一条类似于链表的 use-def 链,链的尾部可以直接由链的头部计算得到,中间计算结果在删除后不影响其他指令的计算。在 LLVM 的实现中,指令合并前会利用算术规则调整指令形式(例如对于满足交换律的计算统一将变量作为左操作数,常数作为右操作数等),提供更多的指令合并机会。
控制流优化¶
控制流优化通过分析代码块的跳转、分支、循环等结构来改进程序性能。
支配树算法¶
支配树是基于有向图中各节点的支配关系构建的一种树形结构。支配树可以帮助确定程序控制流中的关键节点,为诸如代码优化、死代码消除和循环优化等提供基础信息。如何使用支配树进行优化,见 mem2reg 优化 一节。
支配树的构建方法有多种,常见的包括暴力求解和高效的 Lengauer–Tarjan 算法。后者是一种基于深度优先搜索的线性时间算法,广泛应用于实际场景。
完整的支配树算法较为复杂,同学们可以直接调用 API 来构建支配树。如果希望深入了解支配树的理论和求解算法实现,可以参考 OI Wiki 的支配树介绍 或其他相关资料。
循环无关变量移动¶
循环无关变量是指在循环中不随循环迭代次数变化的变量。将这些变量从循环中移出,可以减少循环体内的计算量,提高程序性能。
一个循环无关变量移动的参考实现在 这里。
循环展开¶
代表测例: bitset*.sysu.c、 crypto-*.sysu.c、
instruction-combining-*.sysu.c、 integer-divide-optimization-*.sysu.c
难度:★★★★☆
仅介绍循环次数为常数、可完全展开的循环展开。其原理比较简单,直接看一个例子:
// 循环展开前
while(j<60)
{
ans = ans + 20;
}
// 循环展开后
ans = ans + 20;
ans = ans + 20;
...
ans = ans + 20;
// 结合后续优化
ans = ans + 20 * 60;
循环展开的作用不仅仅是将原本常数的循环展开成非常数的循环,更是要结合后续优化,让循环内的语句能被后续的 Pass 进一步优化。
一个循环展开的参考实现在 这里。
控制流简化¶
代表测例:所有 performance 测例
难度:★★☆☆☆
控制流图(CFG)反映了基本块之间的关系,每个基本块都只有一个进入点(到达某个基本块时,一定是从基本块的第一条指令开始执行)和一个退出点(
ret 或 br 指令),且这些 br
指令会指明将跳转到哪个基本块(1 或 2 个目标基本块),使用有向边将这些可能的跳转连接起来就构成了程序的控制流图。
同学们可以直接调用 Analysi
Pass 来构建控制流图(API 见文档),也可以自己手写一个,只需要从入口基本块开始遍历所有基本块,将
br 指令的边添加到图中即可。
同学们可以使用 工具 来生成 IR 的控制流信息,并进一步生成控制流图。例如,按照如下命令行操作:
clang -S -emit-llvm file.c -o file.ll
opt -dot-cfg -disable-output -enable-new-pm=0 file.ll
dot -Tpng -ofunction.png .function.dot
可以看到控制流图:
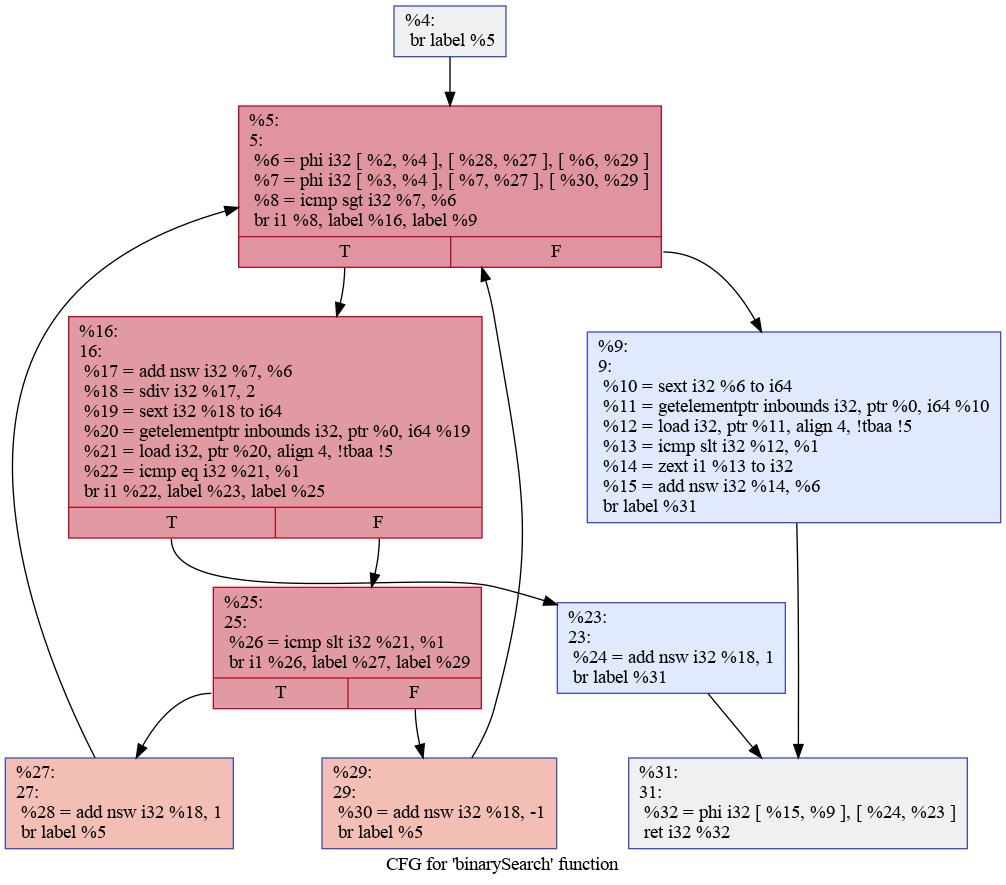
在 task3 的 文档 中,有更详细的介绍。
控制流简化即对控制流图进行简化。
同学们观察 IR 时,可能会发现一些基本块是不可达的,或者一些基本块中只有一条
return
指令,为了执行这条指令,需要一次额外的跳转,会花费更多时间。同时,很多优化方法会局限在一个基本块内,通过合并较小的基本块,可以创建更多优化机会。当然,还可以通过调整基本块的顺序来获得更好的 layout,但这不属于控制流优化的范畴了。
针对以上情况,控制流简化可以通过以下方式进行:
- 删除基本块:不可达的或者只包含一条
return指令的基本块,在做必要调整后可以删除 - 合并基本块:
- 如果一个基本块 B 只有一个前缀基本块 A(也即只有 A 可以到达 B),且该前缀基本块只有一个后缀基本块(也即 A 只能到达 B),则可以将这 A 和 B 两个基本块合并,并删除 A 中的跳转指令。
- 如果多个块跳转到同一个块,且跳转的目标块以
ret结尾,则可以考虑将目标块拷贝多份与前缀块进行合并。注意,这种合并未必是有利的。
其余更多的模式同学们可以查阅资料或者自己思考。
指令级优化¶
指令级优化主要包括指令调度、指令选择等内容,将单条或多条指令转化为运行效率更高的指令。
mem2reg¶
代表测例:所有 performance 测例
难度:★★★★☆
mem2reg 优化是其他所有优化的基础,其为其他优化提供了更大的空间。
考虑到 mem2reg 优化实现比较困难,这一部分代码直接给出。感兴趣的同学可以阅读其 实现。
强度削弱¶
代表测例: bitset*.sysu.c、 crypto-*.sysu,c
难度:★☆☆☆☆
强度削弱(Strength Reduction)将一条高计算复杂度的指令,转化为一条或多条低复杂度的指令。强度削弱是一个很简单但非常有效的优化方式,因为这样的优化机会广泛存在于我们编写的程序之中。在算法比赛中我们常常在编程时使用到这些技巧,但编译器使得我们无需为了性能小心翼翼地编程而获得高性能的程序。下面是一些直观的例子:
// 优化前
int a = x * 8, b = x % 32, c = x * 3;
// 优化后
int a = x << 3, b = x - (x / 32) << 5, c = (x << 1) + x;
具体实现也很简单,只需要识别出上述计算模式(例如对于乘法指令直接判断左右操作数是否为 2 的幂),然后进行指令和操作数的替换即可。大家可以进一步思考,除法是否能够进行类似的优化?如果可以,需要满足什么条件?
代数恒等式¶
代表测例:
难度:★☆☆☆☆
代数恒等式(Algebraic Identities)通过数学规则消除无意义的数学运算,提前将结果算出。例如:
// 优化前
int a = x + 0, b = x - 0;
int c = x * 1, d = x / 1;
int e = x * 0, f = x % 1;
// 优化后
int a = x, b = x;
int c = x, d = x;
int e = 0, f = 0;
具体实现也很简单,只需要识别出上述计算模式(例如对于加法指令直接判断左右操作数是否为 0),然后进行结果的计算与替换即可。
模块级优化¶
模块级优化主要寻求跨函数的优化机会。
函数内联¶
代表测例:所有 performance 测例
难度:★★★☆☆
函数内联是一种常见的编译优化,它可以消除函数调用的开销,同时提供更多的优化机会。用户可以通过关键字
inline
来手动进行函数内联,编译器也会自动做函数内联(通常有限制,当然,我们可以激进一点)。函数内联会将函数调用语句替换为调用函数本身所包含的指令。从 IR 的角度来看,即在函数调用语句对应的地方,插入对应函数的基本块。
具体的实现方法如下:
- 首先需要确定那些函数能被内联。为了确定哪些函数能够内联,需要构造函数调用图(也即 CFG),即确定各个函数之间的相互调用关系。如果一个函数不在函数调用图的某个环内,那么认为这个函数是可以被内联的;反之,该函数其调用的函数可能最后会调用它本身,这个函数就不能进行内联。
- 其次,需要拷贝函数,因为内联插入的基本块与原函数的基本块内容相同,但实际上是不同的数据结构,所以需要对其进行拷贝。
- 最后,需要将拷贝的函数嵌入调用处,并将函数参数替换为传入的参数,然后将调用数为 0 的函数删除。
一个函数内联的实现参考在 这里。
访存优化¶
访存优化通过分析程序的访存模式,消除非必要的访存指令,并提升访存行为的局部性。
死存储消除¶
代表测例: dead-code-elimination-*.sysu.c
难度:★★☆☆☆
死存储消除(Dead Storage Elimination,DSE)与 DCE 相同,都是将无意义的代码识别并删除,两者本质上是同一种优化算法。不同的是,前者主要针对变量初始化、访存指令的消除,而后者主要针对计算指令的消除。对于一个定义了,但并未对输出、返回值和全局变量产生影响的变量,其定义、访存指令可以全部删除。
// 优化前
int main() {
int a = 0;
int b = 1;
a = a + 2;
return b;
}
// 优化后
int main() {
int b = 1;
return b;
}
实现方法与 DCE 相同,在此不作赘述。
高级优化¶
自动向量化¶
代表测例: mm*.sysu.c
难度:★★★★★
包括向量化内存访问与向量化计算。
自动并行¶
代表测例: mm*.sysu.c
难度:★★★★★
自动识别可以并行执行的代码块,并将部分代码由串行执行优化为并行执行,充分利用 CPU 的计算资源。
mem2reg 实现¶
简介和例子¶
在理论课上,各位同学应该了解过静态单赋值(SSA)形式,即每个变量只会被赋值一次。同学们如果认真阅读过 LLVM
IR 的话,应该会发现在 IR 中,每个寄存器都只会被赋值一次,满足 SSA 形式。但是并不是每个变量都只会被赋值一次,每个被
alloca
出来的地址,可能会被多次赋值,这就不保证 SSA 形式了。IR 会通过一些额外的空间来使得寄存器达到 SSA 形式,而这些额外的空间并不是必要的。来看下面这个
例子:
int max(int a, int b) {
if (a > b) {
return a;
} else {
return b;
}
}
翻译成 IR 如下:
define i32 @max(i32 %a, i32 %b) #0 {
entry:
%retval = alloca i32, align 4
%a.addr = alloca i32, align 4
%b.addr = alloca i32, align 4
store i32 %a, i32* %a.addr, align 4
store i32 %b, i32* %b.addr, align 4
%0 = load i32, i32* %a.addr, align 4
%1 = load i32, i32* %b.addr, align 4
%cmp = icmp sgt i32 %0, %1
br i1 %cmp, label %if.then, label %if.else
if.then: ; preds = %entry
%2 = load i32, i32* %a.addr, align 4
store i32 %2, i32* %retval, align 4
br label %return
if.else: ; preds = %entry
%3 = load i32, i32* %b.addr, align 4
store i32 %3, i32* %retval, align 4
br label %return
return: ; preds = %if.else, %if.then
%4 = load i32, i32* %retval, align 4
ret i32 %4
}
我们可以将其转换为如下 IR(这个不是标准的 LLVM IR,仅用来解释中间过程):
define i32 @max(i32 %a, i32 %b) {
entry:
%0 = icmp sgt i32 %a, %b
br i1 %0, label %if.then, label %if.else
if.then:
%retval = %a
br label %return
if.else:
%retval = %b
br label %return
return:
ret i32 %retval
}
此时,可以发现我们删除了大量局部变量,这将节省大量运行时间(这里没有举局部数组的例子,因为想要去除数组,需要复杂的数据流分析,有兴趣的同学可以自己去了解,通常 mem2reg 优化也不会处理数组相关的变量),但是寄存器不再是 SSA 的了(
%retval 被赋值了两次)。这时候我们需要对寄存器重命名,并添加一条 phi
指令(注意, phi 指令只能位于基本块的开头,即 phi 指令前只能是 phi
指令)。 phi 指令的值取决于我们从哪个基本块跳转到该基本块,如果前缀块是
if.then,则其值为 %retval1,否则,其值为 %retval2:
define i32 @max(i32 %a, i32 %b) {
entry:
%0 = icmp sgt i32 %a, %b
br i1 %0, label %if.then, label %if.else
if.then:
%retval1 = %a
br label %return
if.else:
%retval2 = %b
br label %return
return:
%retval = phi i32 [%retval1, %if.then], [%retval2, %if.else]
ret i32 %retval
}
当然,LLVM 中并没有 %retval1 = %a 这样的语句,因此实际上,我们将获得以下结果:
define i32 @max(i32 %a, i32 %b) {
entry:
%0 = icmp sgt i32 %a, %b
br i1 %0, label %if.then, label %if.else
if.then:
br label %return
if.else:
br label %return
return:
%retval = phi i32 [%a, %if.then], [%b, %if.else]
ret i32 %retval
}
而此时,我们就可以用其他优化方法对该 IR 进行更进一步的优化,比如控制流简化可以将
return 基本块与其之前的基本块融合。
查找可优化的 alloca¶
从刚刚的例子,同学们应该能了解到 mem2reg 的基本流程,插入 PHI 指令和变量重命名,实际上在这之前还有一步,就是构建支配树,因为 mem2reg 优化过程中需要使用支配树,所以在开始 mem2reg 前,需要先使用 API 构建好支配树。在构建好支配树后,我们就可以开始进行 mem2reg 优化。
以下代码取自 LLVM 源代码,有删减。
构建支配树可以使用如下指令,其中 fam 是一个 FunctionAnalysisManager:
auto& DT = fam.getResult<DominatorTreeAnalysis>(func);
然后应该查找所有的 alloca 指令,从 alloca
指令出发,找到我们应该处理的所有指令。LLVM IR 会将所有的 alloca 指令放在
entry 块中,所以我们可以遍历 entry 块中的指令,判断该指令是否是 alloca
指令,以及该 alloca 指令是否能够进行 mem2reg 优化(比如如果 alloca
了一个数组的话,那就不对其进行处理)。
以下是一个参考实现,我们可以通过这条 alloca 指令的 User 进行判断,如果这条
alloca 指令的结果(一个指向分配的内存的指针)仅被 load 或者 store
指令使用,且 store 指令将其作为目标地址而不是存储的内容(像指针指向的内存
store,而不是 store 这个指针本身),那么这条 alloca
指令可以被 mem2reg 优化处理。
static bool
isAllocaPromotable(const AllocaInst* AI)
{
// Only allow direct and non-volatile loads and stores...
for (const User* U : AI->users()) {
if (const LoadInst* LI = dyn_cast<LoadInst>(U)) {
// Note that atomic loads can be transformed; atomic semantics do
// not have any meaning for a local alloca.
if (LI->getType() != AI->getAllocatedType())
return false;
} else if (const StoreInst* SI = dyn_cast<StoreInst>(U)) {
if (SI->getValueOperand() == AI ||
SI->getValueOperand()->getType() != AI->getAllocatedType())
return false; // Don't allow a store OF the AI, only INTO the AI.
// Note that atomic stores can be transformed; atomic semantics do
// not have any meaning for a local alloca.
} else {
return false;
}
}
return true;
}
static void
PromoteMemToReg(ArrayRef<AllocaInst*> Allocas, DominatorTree& DT)
{
// If there is nothing to do, bail out...
if (Allocas.empty())
return;
PromoteMem2Reg(Allocas, DT).run();
}
static bool
promoteMemoryToRegister(Function& F, DominatorTree& DT)
{
std::vector<AllocaInst*> Allocas;
BasicBlock& BB = F.getEntryBlock(); // Get the entry node for the function
bool Changed = false;
while (true) {
Allocas.clear();
// Find allocas that are safe to promote, by looking at all instructions in
// the entry node
for (BasicBlock::iterator I = BB.begin(), E = --BB.end(); I != E; ++I)
if (AllocaInst* AI = dyn_cast<AllocaInst>(I)) // Is it an alloca?
if (isAllocaPromotable(AI))
Allocas.push_back(AI);
if (Allocas.empty())
break;
PromoteMemToReg(Allocas, DT);
Changed = true;
}
return Changed;
}
收集 alloca 信息¶
接下来,我们首先需要对每一条 alloca 做处理,每一条 alloca
指令对应着一个局部变量。对这个局部变量的每一次
store,相当于对这个变量的一次定义(define).因为在这个 store
指令之后,下一条 store 指令之前,对这个变量的使用(use),其实都是使用这次
store 存储的值。换句话说,在这之间这个变量的使用,其实只跟这次 store
存储的值有关,而跟这个变量无关。
我们需要找出使用同一个变量(即同一条 alloca 指令的结果)的所有 store 指令和
load 指令,并记录他们所在的基本块。 store 指令所在的基本块称为
DefiningBlock, load 指令所在的基本块称为 UsingBlock。
之所以记录这两种基本块,是因为当我们有了这些信息之后,再结合支配树的信息,我们就可以确定在每一个基本块里,这些变量真正对应的值是什么。具体来说,支配树中记录了节点的支配关系(如果节点 A 支配了节点 B,那么当我们到达节点 B 时,就一定会经过节点 A),如果节点 A 是 DefiningBlock,且节点 A 和 B 之间对于这个变量没有其他的 define,那么在节点 B 时,这个变量的值就一定是节点 A 中所 define 的值,更复杂的情况见后续描述。
我们可以用一个结构体来来存储一条 alloca 的对应信息,如下
struct AllocaInfo
{
SmallVector<BasicBlock*, 32> DefiningBlocks;
SmallVector<BasicBlock*, 32> UsingBlocks;
StoreInst* OnlyStore;
BasicBlock* OnlyBlock;
bool OnlyUsedInOneBlock;
void clear()
{
DefiningBlocks.clear();
UsingBlocks.clear();
OnlyStore = nullptr;
OnlyBlock = nullptr;
OnlyUsedInOneBlock = true;
}
/// Scan the uses of the specified alloca, filling in the AllocaInfo used
/// by the rest of the pass to reason about the uses of this alloca.
void AnalyzeAlloca(AllocaInst* AI)
{
clear();
// As we scan the uses of the alloca instruction, keep track of stores,
// and decide whether all of the loads and stores to the alloca are within
// the same basic block.
for (User* U : AI->users()) {
Instruction* User = cast<Instruction>(U);
if (StoreInst* SI = dyn_cast<StoreInst>(User)) {
// Remember the basic blocks which define new values for the alloca
DefiningBlocks.push_back(SI->getParent());
OnlyStore = SI;
} else {
LoadInst* LI = cast<LoadInst>(User);
// Otherwise it must be a load instruction, keep track of variable
// reads.
UsingBlocks.push_back(LI->getParent());
}
if (OnlyUsedInOneBlock) {
if (!OnlyBlock)
OnlyBlock = User->getParent();
else if (OnlyBlock != User->getParent())
OnlyUsedInOneBlock = false;
}
}
}
};
处理 alloca 指令¶
然后开始对 alloca 指令进行处理。
1、如果一条 alloca 指令的结果没有被任何指令使用,那么对应的 alloca
指令属于死代码,可以直接被删除。
2、如果一条 alloca 指令的结果只被 store 一次,则正常情况下,所有的 load
都使用这次 store 所存储的值,可以直接被这条 store
指令所存储的值替代。特殊情况是, x
没有初始化时,则仍然使用变量,留到后续再进行处理。
3、如果使用某条 alloca 指令结果的所有 load 和 store
都存在于同一个基本块中,这时候就不涉及复杂的基本块支配关系,可以简单处理。
load 的值可以直接用同个 基本块中最近一条 store 指令的值替代。特殊情况是,
load 前不存在 store,同样留到后续处理。
AllocaInfo Info;
for (unsigned AllocaNum = 0; AllocaNum != Allocas.size(); ++AllocaNum) {
AllocaInst* AI = Allocas[AllocaNum];
assert(isAllocaPromotable(AI) && "Cannot promote non-promotable alloca!");
assert(AI->getParent()->getParent() == &F &&
"All allocas should be in the same function, which is same as DF!");
if (AI->use_empty()) {
// If there are no uses of the alloca, just delete it now.
AI->eraseFromParent();
// Remove the alloca from the Allocas list, since it has been processed
RemoveFromAllocasList(AllocaNum);
continue;
}
// Calculate the set of read and write-locations for each alloca. This is
// analogous to finding the 'uses' and 'definitions' of each variable.
Info.AnalyzeAlloca(AI);
// If there is only a single store to this value, replace any loads of
// it that are directly dominated by the definition with the value stored.
if (Info.DefiningBlocks.size() == 1) {
if (rewriteSingleStoreAlloca(AI, Info, LBI, DT)) {
// The alloca has been processed, move on.
RemoveFromAllocasList(AllocaNum);
continue;
}
}
// If the alloca is only read and written in one basic block, just perform a
// linear sweep over the block to eliminate it.
if (Info.OnlyUsedInOneBlock &&
promoteSingleBlockAlloca(AI, Info, LBI, DT)) {
// The alloca has been processed, move on.
RemoveFromAllocasList(AllocaNum);
continue;
}
...
}
rewriteSingleStoreAlloca()¶
rewriteSingleStoreAlloca() 函数完成对只有一条 store
指令的变量的处理,如果一条指令只有一个 store,那我们可以尝试将其 load
指令替换为 store 的值。下面的代码是一个实现参考, replaceAllUsesWith()
函数会将对 load 指令的所有 use 替换为 store 指令的第一个参数:
// Otherwise, we *can* safely rewrite this load.
Value* ReplVal = OnlyStore->getOperand(0);
// If the replacement value is the load, this must occur in unreachable
// code.
if (ReplVal == LI)
ReplVal = PoisonValue::get(LI->getType());
// convertMetadataToAssumes(LI, ReplVal, DL, AC, &DT);
LI->replaceAllUsesWith(ReplVal);
LI->eraseFromParent();
// LBI.deleteValue(LI);
当然,我们并不一定能够成功替换所有示例,我们需要判断 load 指令是否被 store
指令所支配,即当我们执行到某条 load 指令时,我们必须已经执行过 store
指令。只有这样,才能用 store 指令所存储的值替换 load 指令。
这个判断分两种情况:
-
load指令和store指令在同一个基本块中。只需要store指令在load指令前,那么 store 就支配 load。 -
load指令和store指令在不同基本块中如果在不同基本块里。此时,需要利用支配树。DT.dominates(A, B)会返回 A 和 B 两个基本块的支配关系,当 A 支配 B 时,返回true。如果store所在基本块支配load所在基本块,那么store就支配load。
promoteSingleBlockAlloca()¶
promoteSingleBlockAlloca() 函数完成 alloca 指令和使用其结果的 load 与
store 指令在同一个基本块的情况。我们可以将每个 load 的值替换为这个 load
指令前面最近的一个对相同变量的 store 指令存储的值。对每条 store
指令,记录其值以及位置,并按照位置进行排序。对每条 load 指令,二分搜索 store
指令,找到最近的一条 store 指令。
如果 load 指令前面没有 store 指令,有两种情况:
- 这个变量没有对应
store指令,即没有对应的定义,那么将这个变量赋值为未定义值即可:
ReplVal = UndefValue::get(LI->getType());
- 这个
load在所有的store指令之前,那么无法对这个load进行处理,跳过即可,因为可能存在循环,这个load的值可能取决于上一个循环的值。
以上,是对于一些简单情况的 alloca 的处理,接下来将介绍对于更复杂情况下
alloca,应该怎么处理。
支配边界¶
首先对每个 alloca
指令,我们应该在合适的地方插入 phi 指令,这个合适的地方即 store
指令所在基本块的支配边界。
支配边界是支配树中的一个概念,是支配节点和非支配节点的分界线。
若有两个不同的节点\(d \neq m\),且有\(d\ \text{dom}\ m\),则称\(d\) 严格支配 \(m\),\(d\)是\(m\)的严格支配节点,记为\(d\ \text{sdom}\ m\)。节点 \(w\) 是节点\(x\)的支配边界,当且仅当 \(x\) 支配 \(w\) 的一个父节点(前驱节点),同时 \(x\) 不严格支配 \(w\)。
例如下图中,5 的支配边界是 5、4、13、12。因为 5 分别支配它们的父节点 8、6、8、7,且 5 不严格支配 5、4、13、12。
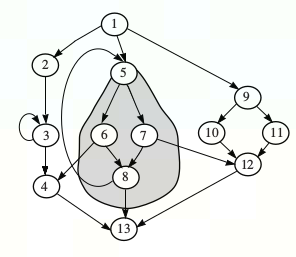
计算支配边界可以通过判断所有被支配的节点的子节点,是否还是被严格支配的,如果不是,那么这个子节点就在支配边界上。
插入 phi 指令¶
被 store 指令支配的节点中的 load,我们能够唯一地确定一个 load 指令,所
load
到的值是什么。但是在非支配节点中,也可能会使用到这个变量,也会有对这个变量的
load,这时候,我们应该如何确定这个 load 的值呢?
在非支配节点,这个 load 所取到的值,取决于在到达这条 load
指令前,程序所走过的路径。路径不同,执行的 store 指令不同, load
到的值也就不同。 phi 指令恰好可以根据不同的来源返回不同的值。前面的例子中,
%retval = phi i32 [%a, %if.then], [%b, %if.else]
指令,会根据前面执行的基本块来确定 phi 指令的值。因此,我们只需要在 store
指令的支配边界插入 phi 指令,就可以在非支配节点中,也能使用 phi 替换掉
load 指令。
为了构造支配边界,这边提供三种方案:
- 暴力,来源编译器设计 第二版 499 页,复杂度较高

-
论文 A linear time algorithm for placing phi-nodes 中提出了一种方法,可以尝试复现这种方法
-
LLVM 中的 Analysis Pass 中已经实现了 2 中提到的方法,可以直接调用相关 API。
当你使用了上面三种方案构建了支配边界后,就可以开始在支配边界中插入相应变量的
phi 指令了。
如果使用方法 1,则可以使用以下算法完成 phi 节点的插入:

因为 phi 指令本身也是对变量的一个 define(类似一个 store),所以 phi
指令所在的基本块的支配边界也需要插入 phi
指令(递归处理,直到所有支配边界都插入完成)。上面的算法有个缺陷,就是会在不必要的地方插入
phi 指令。我们在 store 所在的基本块的所有支配边界都插入了 phi
指令,但是有的支配边界中,本身也有 store 指令,那么这个 phi
指令的值就会被这个 store 所替代, phi
指令相当于白插入了。后面会提到,可以使用 livein block 来避免这种情况。
而方法 2 则是边计算 DF,边计算出 phi
指令的插入点。LLVM 中也提供了相应的实现。示例代码如下:
// If we haven't computed a numbering for the BB's in the function, do so
// now.
if (BBNumbers.empty()) {
unsigned ID = 0;
for (auto& BB : F)
BBNumbers[&BB] = ID++;
}
// Unique the set of defining blocks for efficient lookup.
SmallPtrSet<BasicBlock*, 32> DefBlocks(Info.DefiningBlocks.begin(),
Info.DefiningBlocks.end());
// Determine which blocks the value is live in. These are blocks which lead
// to uses.
SmallPtrSet<BasicBlock*, 32> LiveInBlocks;
ComputeLiveInBlocks(AI, Info, DefBlocks, LiveInBlocks);
// At this point, we're committed to promoting the alloca using IDF's, and
// the standard SSA construction algorithm. Determine which blocks need phi
// nodes and see if we can optimize out some work by avoiding insertion of
// dead phi nodes.
IDF.setLiveInBlocks(LiveInBlocks);
IDF.setDefiningBlocks(DefBlocks);
SmallVector<BasicBlock*, 32> PHIBlocks;
IDF.calculate(PHIBlocks);
llvm::sort(PHIBlocks, [this](BasicBlock* A, BasicBlock* B) {
return BBNumbers.find(A)->second < BBNumbers.find(B)->second;
});
IDF.calculate(PHIBlocks) 计算出了所有需要插入 phi
指令的基本块,具体算法感兴趣的同学可以自行去看论文和源码。注意到,这里还使用了 LiveInBlocks,
IDF.calculate()
在计算插入 phi 的基本块时,只会考虑 LiveInBlocks。如果一个 基本块中,对于某个变量存在一条
store 指令在所有 load
指令之前,那这个基本块不是 live 的。而如果一个基本块,不存在对这个变量的 use(例如
load
指令),且其之后的所有 基本块也不 use 这个变量,那么这个基本块也不是也不是 live 的,我们不用关心。不是 live 的基本块,就不需要插入 phi 指令,我们只在 LiveInBlocks 和支配边界的交集中插入
phi 指令。
实现 ComputeLiveInBlocks() 函数,可以从 Info.UsingBlocks 出发:
- 首先,筛选
Info.UsingBlocks中存在 define 的基本块。如果这些块中,存在某条store指令在最前面,则其不是 live 的,否则是 live 的。 - 然后不断添加已有的 live 的块的前缀,因为这些块的前缀中,对变量的 define 也是 live 的。反复添加,直到无块可加,就找到了所有的 LiveInBlock。
找到需要插入 phi 的基本块后,我们先往块中插入空的 phi 指令,如下:
unsigned CurrentVersion = 0;
for (BasicBlock* BB : PHIBlocks)
QueuePhiNode(BB, AllocaNum, CurrentVersion);
bool
PromoteMem2Reg::QueuePhiNode(BasicBlock* BB,
unsigned AllocaNo,
unsigned& Version)
{
// Look up the basic-block in question.
// PHINode*& PN = NewPhiNodes[std::make_pair(BBNumbers[BB], AllocaNo)];
// If the BB already has a phi node added for the i'th alloca then we're done!
// if (PN)
// return false;
// Create a PhiNode using the dereferenced type... and add the phi-node to the
// BasicBlock.
PN = PHINode::Create(Allocas[AllocaNo]->getAllocatedType(),
getNumPreds(BB),
Allocas[AllocaNo]->getName() + "." + Twine(Version++));
PN->insertBefore(&*(BB->begin()));
// PhiToAllocaMap[PN] = AllocaNo;
return true;
}
然后,进行变量重命名和 phi 指令完善。
变量重命名¶
在插入空 phi 指令之后,我们需要用 store 指令和 phi
指令 define 的值,来替换所有对这个值的 use,包括 load 指令和其他 phi
指令。也即我们需要用 store 的第一个操作数,来替换 load 指令,以及 phi
指令的操作数(incoming values)。
具体算法如下 

简单理解,就是按深搜的顺序,不断使用 store 和 phi
指令更新当前变量的值,并使用当前变量的值替换 load 指令和完善 phi
指令。同学们可以按照这个思路去实现这部分的工作。
YatCC Agent